深層学習DAY4要約2
Section5)Transformer
Seq2Seq
・Encoder-decoderモデルとも呼ばれる。入力系列がエンコードされ、内部状態からデコードされ系列に変化される。
例)翻訳、音声認識、チャットボット
・要は二つの言語モデルを連結した形になっている。
・単語の並びに対して、尤度すなわち文章として自然かを確率で評価する。
・数式的には同時確立を事後確率に分解して表せる。
・時刻t~1までの情報で時刻tの事後確立を求めることが目標
Encoder-decorderモデルの問題点
・文章が長くなると表現力が足りなくなる
Attention
・翻訳先の書く単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用
・Attentionは辞書オブジェクト
・クエリに一致するキーを索引し、対応するValueを取り出す操作であるとみなせる。
Transformer
・RNNを使わない、必要なのはAttentionだけ
・当時のSPTAを遥かに少ない計算量で実現
・英仏の学習を8GP Uで3.5日で達成
Attention
・注意機構には二種類ある。ソースターゲット注意機構と自己注意機構
・自己注意機構により文脈を考慮して各単語をエンコード
Position-wise Feed Forward Networks
・位置情報を保持したまま、順伝播が可能。
Self dot product Attention
・全単語に関するAttention をまとめて計算する。
Multi-head Attention
8個のScaled Dot-attentionの出力をConcat
それぞれのヘッドが異なる種類の情報を収集
decorder
・エンコーダーと同じく6層
・注意機構の仕組みはエンコーダーとほぼ同じ
Position Encording
・RNNを用いないので、単語列の語順情報を追加する必要がある。
Section6)物体検知・セグメンテーション
広義の物体認識タスク
分類:画像に対し、単一または複数のクラスラベル
ーーー物体の位置に興味なしーーー
物体検知:Bounding box
意味領域分割:各ピクセルに対し、単一のクラスラベル
ーーーインスタンスの区別に興味なしーーー
個体領域分割:各ピクセルに対し、単一のクラスラベル
代表的データセット
・VOC12、ILSVRCはBox/画像が小さく、アイコン的な写り。日常感とかけ離れている。
・MSCOCO18、OICID18は部分的な重なり等も見られ、日常生活のコンテキストに近い。
・目的にあったデータセットを選ぶべき
評価指標
適合率:Precision = TP/(TP+FP)
再現率:Recall = TP/(TP+FN)
Confidenceの閾値を変化させることでPrecision -Recall curveが書ける
IoU Intersection over Union
・物体検知においてはクラスラベルだけではなく、物体位置の予測精度も評価したい。
IoU = Area of Overlap / Area of Union

mAP:Mean Average Precision
AP =∮P(R)dR(曲線の下側面積)
mAPはAPの算術平均値
mAP =1/CΣAP
FPS:Flames per Second
応用上の要請から、検出精度に加え、検出速度も問題となる。
物体検知の大枠
・Alexnetの登場を皮切りに、時代はSIFTからDCNNに変わった。
2段階検出機(RCNN、SPPNET、Fast RCNN、Faster RCNN 、RFCN、FPN、Mask RCNN)
・候補領域の検出とクラス推定を別々に行う
・相対的に精度が高い傾向
・相対的に計算量が大きく推論も遅い傾向
1段階検出機(Detector Net、SSD、YOLO、YOLO9000、RetinaNet、CornerNet)
・候補領域の検出とクラス推定を同時に行う。
・相対的に精度が低い傾向
・相対的に計算量が小さく推論も早い傾向
SSD:Single shot detector
1Default boxを用意
2DefaultBoxを変形し、Confを出力
・VGG16をベースとしている
・マップ中の1つの特徴量における、1つのDefaultBoxについて、出力サイズは#Class + 4(オフセット項)
・マップ中の各特徴量にKこのDefault boxを用意するとき、出力サイズはKとなる。さらに特徴マップのサイズがm×nであるとすれば、出力サイズはKmnとなる。
多数のDefault boxを用意することで生ずる問題への対処
・Non-Maimum Supression
1つしか物体が映っていないのに、複数のBounding boxが存在してしまう問題。
対策として、IoUを計算し、IoUが閾値以上であれば、最もConfが高いものだけを残す。
・Hard Negative Mining
背景として判断されるNegative Classが多数存在することが予想される。そのため背景と物体のバランスが不均衡になることが予想される。対策として、最大でも1:3に検出されるように、NegativeのBouding boxを削る。
Semantic segmentation
・解像度が層を進むごとに落ちていく
→入力時と異なる解像度をどのようにして元の解像度に戻すのか(アップサンプリング)の方法が問題になっていた
De convolution\Transposed convolution
・通常のConvolution層と同様に、カーネルサイズ、パディング、ストライドを指定する。
・逆畳み込みと呼ばれることも多いが、畳み込みの逆演算ではないことに注意。
輪郭情報の補完
・プーリング5の情報をいきなり元の情報までアップサンプリングするのではなく、まずはプーリング4の情報までアップサンプリングし、各要素を足し合わせる。これを繰り返し元の情報まで戻す。
Unpooling
・プーリングした時の位置情報を保持しておく方法。
ダイレイト畳み込み
プーリングを用いずに受容野を広げる方法
深層学習DAY4要約1
Section1)強化学習
強化学習とは
・長期的に報酬を最大化できるように環境の中で行動を選択できるエージェントを作ることを目標とする機械学習の一分野。行動の結果として与えられる利益をもとに、行動を決定する原理を改善していく仕組み。
探索と利用のトレードオフ
環境について事前に完璧な知識があれば、最適な行動を予測し、決定することは可能。
強化学習の場合、上記の家庭は成り立たないとする。不完全な知識をもとに行動しながら、データを収集。最適な行動を見つけていく。
過去のデータでベストとされる行動のみを常に取り続ければ、他にもっとベストな行動を見つけることはできない。一方で未知の恋有働のみを常に取り続ければ、過去の経験が活かせない。
・目標が異なる。教師あり、教師なし学習では、データに含まれるパターンを見つけ出す、及びそのデータから予測することが目標。
強化学習では、優れた方策を見つけることが目標。
強化学習の歴史
・冬の時代があったが計算速度の進展により大規模な状態を保つ場合の、強化学習を可能としつつある。
・関数近似法と、Q学習を組み合わせる手法の登場
・Q学習とは、行動価値観数を、行動するごとに更新し、学習を進める手法。
・関数近似法とは価値観数や方策関数を関数近似する手法のこと。
価値関数
・価値を表す関数としては、状態価値関数と行動価値関数の2種類がある。
・ある状態の価値に注目する場合は、状態価値関数。
状態と価値を組み合わせた価値に注目する場合は、行動価値観数。
方策関数
・方策関数とは、方策ベースの強化学習手法において、ある状態でどのような行動を取るのかの確率を与える関数のこと。
方策勾配法について
・方策反復法:方策をモデル化して最適化する手法。
・Jとは方策の良さで定義する必要がある。
・定義方法は平均報酬と割引報酬話がある。
上記の定義に対応して行動価値関数の定義を行う。
Section2) AlphaGo
Alpha go Lee
・Policy Netは19×19の着手予想確率が出力される
・Value Netは現局面の勝率を−1~1で表したものが出力される。
・Rolloutpolicy:NNではなく線形の方策関数。探索中に高速に着手確立を出すために使用される。
PolicyNetの教師あり学習
・KGS GO Serverの寄付データから3000万局分の教師を用意し、教師と同じ着手を予測できるよう学習を行なった。
ValueNetの学習
・Policy Netを使用して対極シミュレーションを行い、その結果の勝敗を教師として学習した。
モンテカルロ木探索
・Alphagoのモンテカルロ機探索は選択、評価、バックアップ、成長という4つのステップで構成される
ResidualNetwork
・ネットワークにショートカット構造を追加して、勾配の爆発消失を抑える効果を狙ったもの。ResidualNetworkを使用することにより、100層を超えるネットワークでの安定した学習が可能となった。
Seciton3) 軽量化・高速化技術
分散深層学習とは
・深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。
。複数の計算資源を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい。
・データ並列化、モデル並列化、GPUによる高速技術は不可欠である。
データ並列化
・親モデルを各ワーカーに小モデルとしてコピー
・データを分割し、各ワーカーごとに計算させる。
同期型
・各ワーカーが計算が終わるのを待ち、全てのワーカーの勾配が出たところで勾配の平均を計算し、おやモデルのパラメータを更新する。
非同期型
・各ワーカーはお互いの計算を待たず、各個モデルごとに更新を行う。
・学習が終わった子モデルはパラメータサーバーにPushされる。
・新たに学習を始めるときは、パラメータサーバからPopしたモデルに対して学習していく。
同期型と非同期型の比較
・処理スピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
・非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
・現在は同期型の方が精度が良いことが多いので、主流となっている。
モデル並列化
・親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後、一つのモデルに復元。
・モデルが大きいときはモデル並列化を、データが大きいときはデータ並列化をするとよい。
モデル並列
・モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
GPUによる高速化
・GPGPU(Gneral-purpose on GPU)元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
・CPU:高性能なコアが少数、複雑で連続的な処理が得意
・GPU:比較的低性能なコアが多数、簡単な並列処理が得意、ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
GPGPUの開発環境
CUDA
・DL用に提供されているので使いやすい
・GPUで並列コンピューティングを行うためのプラットフォーム
・オープンな並列コンピューティングのプラットフォーム
・DL用の計算に特化しているわけではない
モデルの軽量化の利用
・モデルの軽量化はモバイル、IoT機器において有効な手法
・モデルの軽量化は計算の高速化と省メモリ化を行うためモバイル、IoT機器と相性が良い手法になる。
軽量化の手法
・量子化、蒸留、プルーニング
・量子化とは、ネットワークが大きくなると大量のパラメータが必要になり、学習や推論に多くのメモリと演算処理が必要になる。
・通常のパラメータの64Bit浮動小数点を32Bitなど回の精度に落とすことでメモリと演算処理の削減を行う
量子化の利点と欠点
・利点:計算の高速化、小メモリ化
・欠点:精度の低下
蒸留とは
・精度の高いモデルはニューロンの規模が大きなモデルになっている。そのため、推論に多くのメモリと演算処理が必要。規模の大きなモデルの知識を使い、軽量なモデルの作成を行う。
モデルの簡略化
・学習済みの精度の高いモデルの知識を軽量なモデルへ継承させる
・蒸留は教師モデルと生徒モデルの2つで構成される。
・教師モデル:予測精度の高い、複雑なモデルやアンサンブルされたモデル
・生徒モデル教師モデルをもとに作られる軽量なモデル
・教師モデルの重みを固定し、生徒モデルの重みを更新していく。
・誤差は教師モデルと生徒モデルのそれぞれの誤差を使い重みを更新していく
プルーニング
・ネットワークが大きくなると大量のパラメータが必要になるが、全てのニューロンの計算が精度に寄与しているわけではない。
・モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化が見込まれる。
Section4)応用技術
Mobile Nets
・ディープラーニングモデルは精度は良いが、その分ネットワークが深くなり計算量が増える。
・計算量が増えると、多くの計算リソースが必要で、お金がかかってしまう。
・ディープラーニングモデルの軽量化・高速化・高精度化を実現。
Depthwise convolution
・入力マップのチャンネルごとに畳み込みを実施(チャンネルごとのフィルタを一つにし、重みを共有する)
・出力マップをそれらと結合(入力マップのチャンネル数と同じになる)
・通常の畳み込みカーネルは全ての層にかかっていることを考えると計算量が大幅に削減可能
・各層ごとの畳み込みなので層の間の関係性は全く考慮されない。通常はPW畳み込みとセットで使うことで解決
Pointwise Conovlution
・1×1畳み込みとも呼ばれる(正確には1×1×c)
・入力マップのポイントごとに畳み込みを実施
・出力マップ(チャネル数)はフィルタ数分だけ作成可能
MobileNetのアーキテクチャ
・Depthwise Separable Convolutionという手法を用いて計算量を削減している。通常の熱海込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise convolutionとPointwiseConvolutionと呼ばれる演算によって個別に行う。
・Depthwise convolution絵はチャネルごとに空間方向へ畳み込む。すなわちチャネルごとにDk×Dk×1のサイズのフィルターをそれぞれ用いて計算を行うため、その計算量はH×W×C× DK×Dkとなる。
・次にDepthwise Convolutionの出力をPointwise Convolutionによってチャネル方向に畳み込む。すなわち出力チャネルごとに1×1×Mサイズのフィルターをそれぞれ用いて計算を行うため、その計算量はH×W×C×Mとなる。

Batch Norm
・レイヤー間を流れるデータの分布を、ミニバッチ単位で平均が0・分散が1になるように正規化。
・Batch Normalizationはニューラルネットワークにおいて、学習時間の短縮や初期値依存低減、過学習の抑制など効果がある。
・問題点として、バッチサイズが小さい条件下では、学習が収束しないことがあり、代わりにLayer Normalizationなどが使われることが多い
Layer Norm
・それぞれのサンプルの全てのピクセルが同一分布に従うよう正規化
Instance Norm
・Channelも同一分布に従うよう正規化
WaveNet
・生の音声波形を生成する深層学習モデル
・Pixel CNNを音声に応用したもの
・時系列データに対して畳み込み(ダイレイト畳み込み)を適用する。
・ダイレイト畳み込みとは、層が深くなるにつれて畳み込むリンクをはなす
・ダイレイト畳み込みを用いた際の大きな利点は単純なConolutionConolution Layerと比べて受容野が広いことである。
深層学習DAY3、4確認テスト
Section1)再帰型ニューラルネットワークの概念

中間層(隠れ状態ベクトル)に対して掛けられる重みがある。
隠れ状態ベクトルは時系列データの時間関係を記録し、保持する。
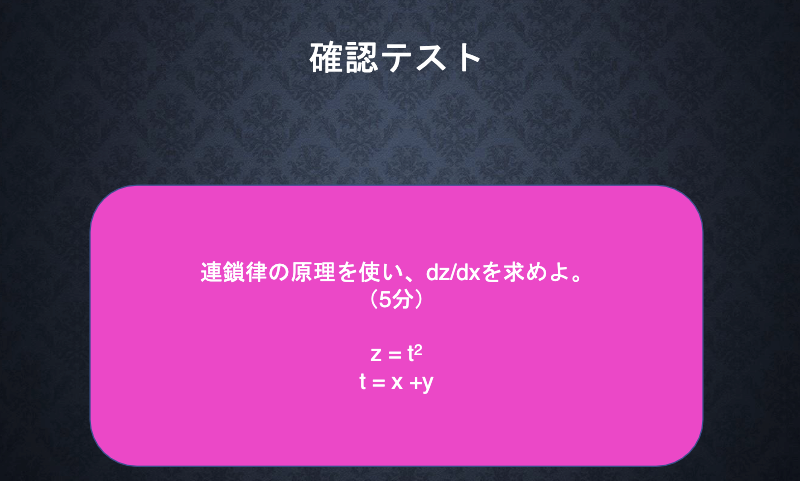
dz/dt * dt/dx = 2t *1 = 2(x + y)
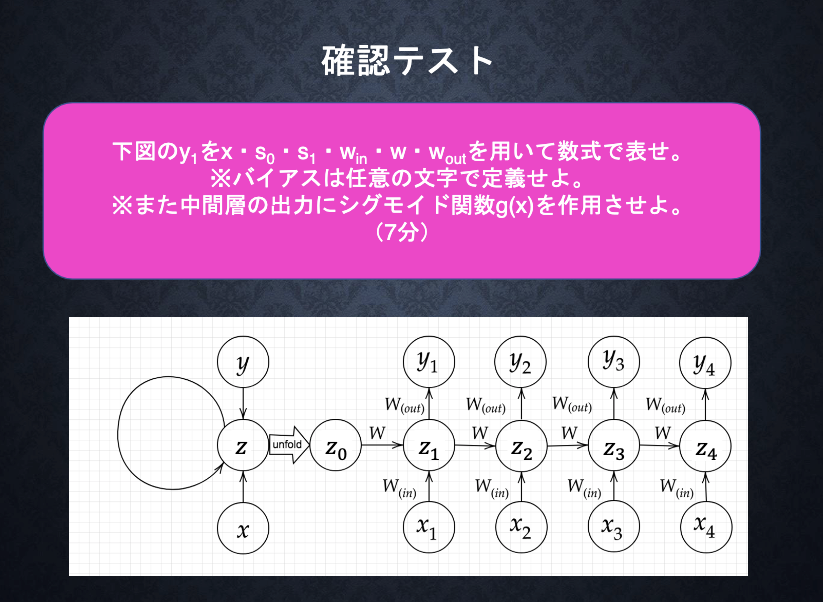
s1 = w_in*x1 +w*s0+b
y1 = g(w_out*s1+c)

x=0の時、y=0.5
y' = y(1-y)= 0.5*(1-0.5)=0.25

出力ゲートで覚える必要がないと判断する。

LSTMは4つのゲートを持つ。そのためパラメータ数が多いので、計算負荷が高い。
CECの問題点は記憶機能のみで、学習機能がない。
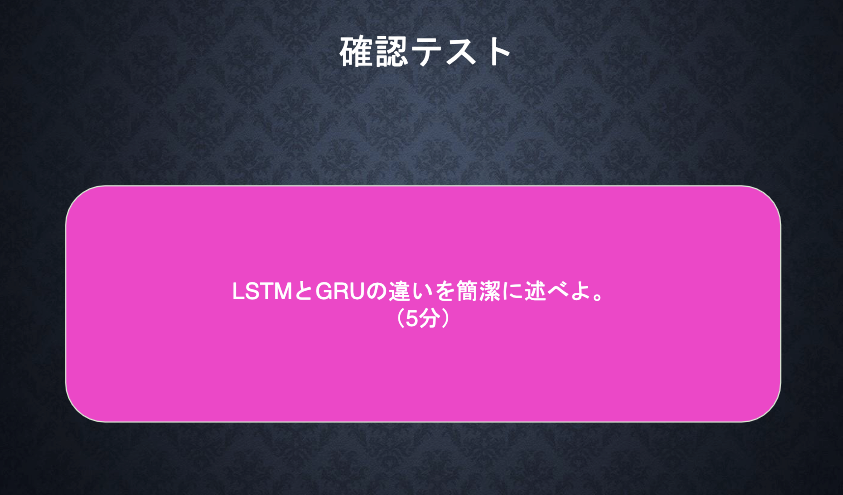
LSTMは忘却、出力、入力ゲート、CECの4つのゲートがある。一方でGRUは更新とリセットゲートの二つを持つ。

2

Seq2Seq:一問一答しかできない
HRED:過去の発話の内容から、次の発話を生成する
HRED:文脈を意識した返答はするが、「そうだね」などの短いよくある答えを選ぶ傾向がある。
VHRED:VAEの潜在変数の概念を追加し、モデルにバリエーションを持たせた

確率分布

RNNは時系列データを処理するのに適している。
Word2vecは単語の分散表現を得るために使用する。
Attentionはデータに対して、関連度(内積)を得ることで、学習を進める。

い:H×W×C×K×Kとなる。
う:出力マップの計算量はH×W×M×Cとなる

ダイレイト畳み込みと呼ばれる。

受容野を広げることができる。
深層学習DAY3要約
Section1)再帰型ニューラルネットワークの概念
・RNNとは
時系列データに対応可能なニューラルネットワークである。
時系列モデルを扱うには、初期の状態と過去の状態tー1の状態を保持し、そこから次の時間でのtを再起的に求める再起構造が必要になる。
・時系列データとは?
時間的順序を追って一定間隔ごとに観察され、しかも相互に統計的依存関係が認められるようなデータの系列。(音声データ、テキストデータなど)
・BPTTとは
誤差逆伝播法の一種である。
RNNにおけるパラメータ調整法の一種である。
Section2) LSTM
・RNNの課題
時系列を遡れば遡るほど、勾配が消失していくため、長い時系列の学習が困難。
解決策として、ネットワークの構造自体を変えて解決したものがLSTM
・勾配消失問題
誤差逆伝播法が下位層に進んでいくほど勾配が小さくなっていく。そのため入力層付近で、学習が進まなくなる。
・勾配爆発
勾配が層を逆伝播するごとに指数関数的に大きくなること
・CEC
中間層で肝になる機能、記憶機能だけ持つ。これまでの入力値や中間層を記憶させる。
・入力ゲート
入力された値をどの程度記憶するのかを決定する。
・出力ゲート
次時刻に出力させる値をどの程度中間層の記憶を使うかを決める。
・忘却ゲート
過去の情報がいらなきなった場合に、どの程度忘却させるかを決める。
・のぞき穴結合
CECの保存させている過去の情報を任意のタイミングで、他のノードに伝播させたり、忘却させたりしたい。
→CEC自身の値に重み行列を介して伝播可能にした構造。
Section3) GRU
・LSTMの課題
LSTMではパラメータ数が多く、計算負荷が高くなる問題があった。
GRUではそのパラメータを大幅に削減し、精度は同等またはそれ以上が望めるようになった構造。
ゲートはリセットと更新ゲートの二つ。
Section4)双方向RNN
過去の情報だけではなく、未来の情報を加味することで、精度を向上させるためのモデル。
実用例として、文章の推敲や、機械翻訳等がある。
双方向RNNでは、順方向と逆方向に伝播した時の中間層表現を合わせたものが特徴量になる。
Section5)Seq2Seq
Seq2Seqとは
Encoder-decoderモデルの一種を指す。
使用用途として、機械と岩や、機械翻訳に使用されている。
Encoder RNN
ユーザーがインプとした情報を、単語等のトークンに区切って渡す構造。
Taking:文章を単語等のトークン事に分割し、トークン毎のIDに分割する。
Embedding:IDからそのトークンを表す分散表現ベクトルに変換。数字の並びが似かよっている事は似かよった意味を持つ単語という事になる ⇒ 単語の意味を抽出したベクトル。
Encoder RNN:ベクトルを順番にRNNに入力していく。
最後のベクトルを入れた時の隠れ状態をFinal stateとして取っておく。
Decoder RNN
システムがアウトプットデータを、単語等のトークンごとに生成する構造。
Decorder RNNのFinal stateをDecoder RNNのInitial stateととして設定し、Embeddingを入力。
Sampling:生成確率に基づいてトークンをランダムに選ぶ
EMbedding:2で選ばれたトークンをEmbeddingしてDecorder Rnnへの次の入力とする
Detokenize:1ー3を繰り返し2で得られたトークンを文字列に直す
Seq2Seqの課題
一問一答しかできない
問に対して文脈も何もなく、ただ応答が行われる。
HREDとは
・過去の発話から次の発話を生成する。
・Seq2Seq ±ContextRNN
VHREDとは
HREDに、VAEの潜在変数の概念を追加したもの。
オートエンコーダとは
教師なし学習の一つ。そのための入力データは訓練データのみで、教師データは利用しない。
VAE
通常のオートエンコーダーの場合、何かしらの潜在変数zにデータを押し込めているものの、その構造がどのようなものかわからない。VAEはこの潜在変数zに確率分布を仮定したもの。VAEはデータを潜在変数zの確率分布という構造に押し込めることを可能にします。
Section6)Word2Vec
学習データからボキャブラリを作成
大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能にした。
Section7) Attention
Seq2Seqでは長い文章への対応が難しい。(隠れ層ベクトルが固定長だから)
解決策として、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要。入力と出力のどの単語が関連しているのか、関連度を学習する仕組み。
深層学習DAY2要約
Section1 勾配消失問題
誤差逆伝播法が下位層に進むにつれて、勾配がどんどん緩やかになっていく。
そのため、勾配降下法による更新では下位層のパラメータはほとんど更新しない。
・ シグモイド関数は大きい値、小さい値だと勾配が微小であるため学習が進まない。
・勾配消失問題を回避するために、活性化関数をReLuにする、初期値の設定をXavierの初期値(シグモイド関数ReLU)、Heの初期値(ReLU)に設定する、バッチ正規化がある。
・ReLUでは勾配をそのまま下層に流すため、勾配消失問題が生じにくい。
・Xavierの初期値は前の層のノード数で除したの正規分布に従う分布から取得する。
・Heの初期値は前の層のノード数で除した値に√2を乗算した、正規分布から取得する。
・バッチ正規化とは、ミニバッチ単位で入力値のデータの偏りを抑制する手法。
Section2 学習率最適化手法
・学習率の値が大きい場合、最適値にたどり着かず発散してしまう。
・学習率の値が小さい場合、発散することはないが、収束するまでに時間がかかる。大域的最適値に収束しづらくなる。
モメンタム:局所的最適解にはならず、大域的最適解になる。谷間についてから最適値に行くまでの時間が早い。
AdaGrad:繰り返し数が増えると勾配の更新値が小さくなるため、最初は大きく学習し、時間が経つと小さく学習することが可能になっている
RMSprop:学習率を移動平均によって求めるため、学習がある程度進んだ後に勾配が急激に変化しても、対応することができる。
Adam:モーメンタムとRMSpropの合わせ技
Section3 過学習について
過学習とは、テスト誤差と訓練誤差で学習曲線が乖離すること
ドロップアウトとはランダムにノードを削除して学習させること
メリットとしてデータ量を変化させずに、異なるモデルを学習させていると解釈できる。
Section4畳み込みニューラルネットワークの概念
CNNとは:主に画像に用いられるが、時限に関して関連があるデータ全てに使用することができる。代表的なCNNのモデルに、LeNetがある。
畳み込み層、プーリング層を繰り返し行い、 最後に全結合層を通し、出力する。
畳み込み層:フィルタと呼ばれるN×Nの行列と畳み込み演算を行い、その後バイアスを追加し入力画像からより低次元の特徴量を作り出す。
フィルター:全結合層でいう重みに相当する
バイアス:フィルターと違い、一律に同じ値を足す。
パディング:入力データの周囲に固定のデータ(0など)を埋めること
ストライド:フィルターを適用する位置の感覚
チャンネル:奥行き方向のデータ
全結合層で画像を学習した際の課題
・画像の場合、縦横チャンネルの三次元データだが、これが全結合層では一次元のデータとして処理される。そのためRGB間の関連性が学習に反映されない。
プーリング層:重みがなく、対象となる領域から平均値や最大値を取り出す処理をする。
Section5 最新のCNN
Alexnetのモデル
・5層の畳み込み層及びプーリング層など、それに続く3層の全結合層から構成される。
・Flattenと呼ばれる画像を一次元に変換する処理がある。
・過学習を防ぐと施策として、サイズ4096の全結合層の出力にドロップアウトを使用している。