深層学習DAY3、4確認テスト
Section1)再帰型ニューラルネットワークの概念

中間層(隠れ状態ベクトル)に対して掛けられる重みがある。
隠れ状態ベクトルは時系列データの時間関係を記録し、保持する。
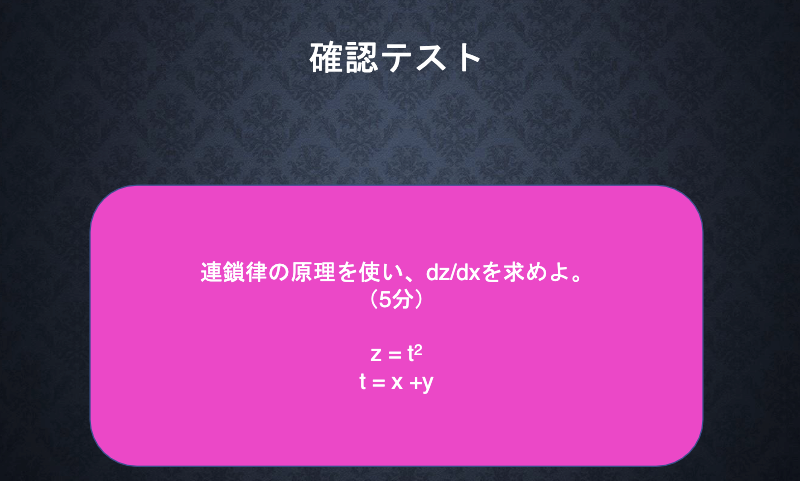
dz/dt * dt/dx = 2t *1 = 2(x + y)
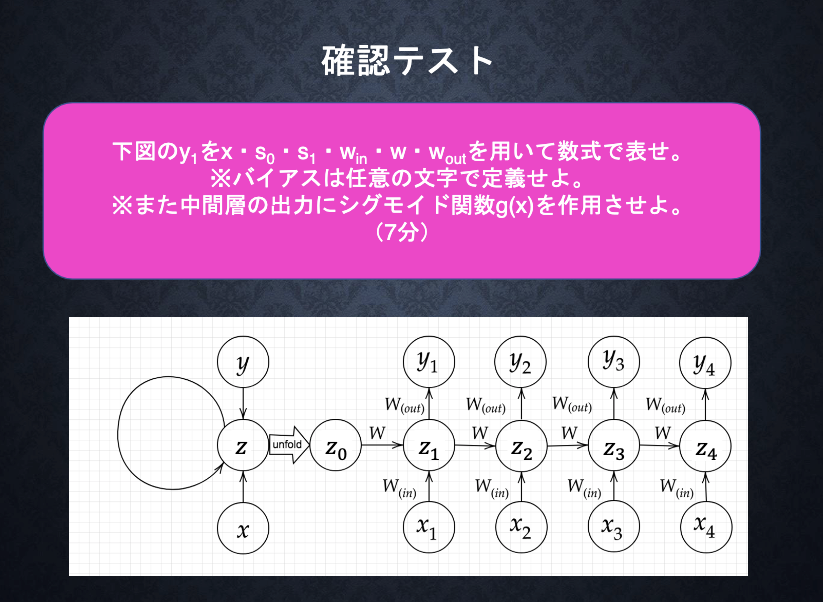
s1 = w_in*x1 +w*s0+b
y1 = g(w_out*s1+c)

x=0の時、y=0.5
y' = y(1-y)= 0.5*(1-0.5)=0.25

出力ゲートで覚える必要がないと判断する。

LSTMは4つのゲートを持つ。そのためパラメータ数が多いので、計算負荷が高い。
CECの問題点は記憶機能のみで、学習機能がない。
LSTMは忘却、出力、入力ゲート、CECの4つのゲートがある。一方でGRUは更新とリセットゲートの二つを持つ。

2

Seq2Seq:一問一答しかできない
HRED:過去の発話の内容から、次の発話を生成する
HRED:文脈を意識した返答はするが、「そうだね」などの短いよくある答えを選ぶ傾向がある。
VHRED:VAEの潜在変数の概念を追加し、モデルにバリエーションを持たせた

確率分布

RNNは時系列データを処理するのに適している。
Word2vecは単語の分散表現を得るために使用する。
Attentionはデータに対して、関連度(内積)を得ることで、学習を進める。

い:H×W×C×K×Kとなる。
う:出力マップの計算量はH×W×M×Cとなる

ダイレイト畳み込みと呼ばれる。

受容野を広げることができる。